|
匿名
发表于 2023-4-15 09:52:20
阅读模式
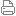


| |
|
huahua83326
2023-4-15 09:56:11
显示全部楼层
| |


创业教程秘籍一:为什么要创业? 这是在你创业前必须先问自己的第一个问题,这点事很重要的,大家一定要记住!! 答案一 ...

1、风险承受能力不同。穷人失败意味着倾家荡产,乃至家庭亲情。 2、融资能力不同。穷人只能贷款、存款、借款来创业 ...

这几年生意的不好做,更是引发了大量的创业潮,但是你会发现,那些所谓出来创业的人们,最后往往都亏损到几乎破产 ...

创业!是每一个人的梦想,也是发家致富的途径之一。现在非常提倡创业,在当前互联网时代里,确实有很多方面适合创业, ...

你创业成功了吗?说说你的创业经历 看看网友们的创业分享,莫名难言! 云裂变汇聚微信运营,微信小程序 ...

河南郑州大学的3名95后同学在学校开起了无人看守商店,试营业期间日营业额就达到了5000元。胡育华说,资金是以前自己 ...

全国现在超过700万人到农村创业,并且还在快速增加。那么农村有哪些小本项目适合农民工返乡创业呢? 第一、野生土产经 ...

导语:人到中年,你会选择创业拼一把吗?笔者做了一个调查,很多人的回应都是两个字:不敢,因为笔者阶层的原因,笔者 ...

很多人上班感觉很没意思,就开始创业,现在创业的门槛比较低,注册一个公司也花不了多少钱,好多人甚至一气之下注册了 ...

大家好,我是华三少,谢谢大家的关注,今晚收拾的有点迟,回来晚了,更新的晚了。开业七天了,从第一天的惨淡开场,到 ...

冉宏伟 封面新闻记者 谢颖 摄影报道 田埂上,火红的玫瑰花在风中摇曳;田间,一个着白色T恤的小伙子,蹲在一群上了 ...

你有想过创业吗?你有想过低成本创业吗?王健林透露今年的时机,趋势是最好的,现在国内国外的企业都把握趋势,都顺势 ...

我是武汉火凤凰云创空间,创业人的学习圈子 我从2007年至今,做过2次生意,用现在时髦的话叫做创业。 两次创业都是 ...

前段时间没写完,一是我不知道应该怎么把它给表达出来,文采有限。二是有些逃避,不想把自己失败的事在拿出来。 几年 ...

拼了命地挣钱 熬夜加班 透支身体 结果会怎样? 一边熬夜到天明 一边敷着最贵的面膜 靠身体赚的钱 终究要用健康 ...

纸来也创始人白传豪有着5次创业经历。 文 | 铅笔道记者 南镜 纸来也创始人白传豪分享了这样一组数据:“90%的男性 ...

文/一刘 昨天,一刘说了快递行业存在的五大痛点: 痛点一,不送上门。 痛点二,个人信息容易泄漏。 痛点三,容易 ...

你听过最传奇的人生是什么,今天介绍给大家的人物就是这位老太吴胜明,她年轻的时候也曾经是一位上海的千万富婆,这些 ...

幼年患病致残,四处艰难求医,父亲早亡生活困顿,饱受世人异样的眼光和议论……当生命中遇到这些,我们能怎么办?山 ...

如果二十一岁毕业,三十岁的你在干什么?9年可以成就多大的事业,难以想象,但是永远不要低估自己的能力。 和很很多 ...

袁兰,21岁,四川师范大学公共事业治理专业大二学生,与同乡、同班、同寝室好友王菊园经营着一家网店卖零食。两人的创 ...

朱明跃是一个重庆人,当过三年老师,后来做了记者。 他在黔江晚报、酉阳电视台等地方都工作过,后来到了重庆晚报。 ...

2001年夏天,王麒诚还是一名大二学生,担任着校学生会实践部部长一职,经常到校外拉赞助,在一次校外事件活动中,他发 ...

家住云南乡村的苏建益,2002年考上长春师范大学政法学院后,他便开始了在长春的创业生涯,父母靠种地和养奶牛供他读书 ...

张军经营着一家羊肉煲店,短短一个月时间,竟然将8万元变成了一百万元,就连他自己都觉得不可思议。 哥哥的提醒让张 ...

小杜和小陈是今年的大学毕业生,很多同学正苦恼找工作的时候,他们已经着手开拓事业:职业农民。 有家公司与华农合作 ...

综合排名NO.1 创业新模式、新浪潮开一家网上超市 理由:国家肯定分享经济,大势所趋,成本小,致富快。 自己开 ...

转化能力 营销落地 请您点击右上角关注:转化能力 针对职场,市场营销,经营规划领域的总经理、营销总监、渠道总监 ...

作者 | 创业投资家 来源 | 创业投资家 35岁,混了十年什么都没有,你这位朋友没能获得成功的地方就是想太多,害怕失 ...

她本来是一个月薪五万的自由职业者,但是却辞职创业。然而现在,她的微博@暴走济南作为一个短视频原创内容创作平台, ...

如果有人问你创业三次都失败还有信心在继续创业吗,我想大部分人的回答都是一次失败可能就不会在尝试了何况是三次,但 ...

来源:Spenser(ID:spenserandhk) 最近身边朋友换工作的越来越多了,有的已经从体制内辞职,有的在传统高大上公司 ...

世界杯期间,每当深夜,在上海杨浦区大学路,95后外卖小哥涂兴国都会停在路边看球。 他说自己曾开公众号创业,“一年 ...

无论是初出社会,还是在社会上行走了一段时间,相信许多人都会有“创业-暴富”的想法。小米赴港上市三天来,总市值达 ...

最近宁德真是好事连连! 就在今年!2018! 宁德将完成一大批好政策好项目 每一位宁德人都将 身!价!爆!涨! 2 ...
小编在互联网已经摸索了很长时间了,什么坑都见过,一直没有一个很大的突破,直到看到这些资料。慢慢的开始有了收入, ...

1 数码维修店 手机、相机、笔记本的大量普及已经向人们宣告了一个数码时代的到来,而数码产品极高的损坏率也为创业者 ...

1,捞钱最快的小本创业项目:网上农业经纪人 改变传统的农产品经营方式,依托当地特色农产品,在网上开办农业 ...

如何在互联网上无本创业呢,我相信这个问题很多人也很迷茫。其实赚钱是有秘密的,这些秘密都是些潜规则,每个项目每 ...

云裂变汇聚微信运营,微信小程序,淘客运营,区块链等专业领域,每天更新最实用的微信运营,微信小程 ...

一个怀揣创业梦想的人,在浙江台州打工几年,看到那边有个叫XX的奶茶店生意挺火爆,于是2016年年底就想在老家也开一家 ...

如今创业环境相当难。有这么一句话,创业难,守业更难,对于创业者而言,现今的市场是竞争力是非常残酷的,如果你没有 ...

幸福是奋斗出来的。这句话用在任何行业,都是真话。在山东省茌平县贾寨镇前寨村“菏泽呛面高桩馒头”店,店主是一对9 ...

快递代理点 农村快递,随着农村人上网越来越普及,好多人都通过淘宝、京东等网上商城来购物,可这些地方正是快递行业 ...

温馨提示:阅读前,请点击右上角“关注”,就可以每天第一时间免费获取“东方思维管理课堂”分享的职场及管理知识啦。 ...

打工 VS 创业 创业前 VS 创业后 云裂变汇聚微信运营,微信小程序,淘客运营, ...

你是否了解中国8400万残疾人,目前的生存状态如何,他们如何就业,他们的未来在哪里? 全社会如何在不损伤自身利益的 ...

8月25日,浙江温州乐清市公安局通过官方微博通报了发生在该市的一起刑事案件,确认此前失踪的赵女士,已被滴滴顺风车 ...

过去创业条件有利,成功的人很多,现如今创业,是失败的比较多。有些人不愿意一辈子打工,然后辞职创业,对自己的生活 ...

如今,“开夫妻店”成了创业大军中的潮流,夫妻两人合作上更紧密,沟通上障碍也很少,十分适合共同创业。 今天小编 ...

随着网络游戏的兴起,特别是移动网络游戏的兴起,越来越多的年轻人爱上了来手游。但游戏不仅仅可以用来娱乐,还可以用 ...
你还在为不知道如何才能经营好自己的人脉而犯愁吗?你还在为创业时候身边没有人帮你而犯愁吗?其实人类是个社会性动物 ...

现在,越来越多的年轻人选择走上了创业这条路,但是,对于很多年轻人来说,资金不足,是其创业首先便要面对的的第一个 ...

中国是人情社会,是全世界最讲人情和关系的国家。有关系,什么事情都好办。没关系,最容易的事情也要掂量掂量。关系是 ...

李嘉诚:不想当将军的士兵不是好士兵,但是一个当不好士兵的将军一定不是好将军。人永远不要忘记自己第一天的梦想,你 ...

今天给大家分享一下个人赚钱的相关案例和资源教程,不知道怎么赚钱就去学习和借鉴。资料很多,包含:创业点子,创业思 ...

文|AI财经社 刘雪儿 编辑 |陈芳 在河南郑州见到苗壮时,很难想象他刚刚创业失败。39岁的他皮肤白皙,身材精悍, ...

《首届中国相声小品大赛》评委姜昆昨日受访时透露,自己曾创业做中国相声网失败,一度赔光前半生积蓄。谈到此次参加 ...

创业贷款配图 一个人老是以自己的眼光看待这个世界就会认为自己总是对的,我们习惯站在别人的角度去看,那么我们就是 ...

人生在世,无非就是吃喝二字,我们目前所做的一切满足的基本需求就是吃喝,人们通过劳动满足自己的日常的吃穿用度, ...

马云谈中国最暴利的4大冷门行业,几乎零成本,适合穷人创业起家 独家:马云世界智能大会演讲 与凤凰同飞,必是俊 ...

最近新出了一部电视剧《创业时代》,该剧一上映就引起了热烈的讨论。主要是因为该剧的阵容。该剧是由:黄轩、杨颖、宋 ...

1.玉米面条机 玉米面条机是在挤压机械的基础上,研制成功的一种新型单(双)螺杆食品挤压机,该机具有设计新颖、结构 ...

马云透露:年底这5个行业人丢饭碗!谁都逃不掉,你何去何从 如今社会除了公务员、事业编制的“铁饭碗”外,似乎就 ...

在以前的农村,生活没有现在那么好,经济也处于刚发展的阶段,一年辛辛苦苦下来基本没有什么钱,农村家庭想建房,日常 ...

1、露天酒吧 在酷热难耐的夏天,人们都愿意饮上几杯凉爽可口的啤酒消暑。创业者可以选择在街头广场,公园一角或居 ...

第一次创业,难免会遇到问题,经常要花钱买教训。所以,投入越多,交的“学费”也越多,因此很多人会选择小成本的摆地 ...

近期,和许多朋友一起交流创业话题,感觉大家都在寻找好项目,我一直强调,适合自己的就是好项目,作为普通人,我建议 ...

穷人不敢创业是为什么呢?因为害怕失去,害怕自己辛辛苦苦积攒下来的血汗钱赔个精光。没关系,下面这几个小本创业项目 ...

当今社会作为80后,时代赋予了我们太多的责任,我们没赶上70后分房子的年代,不得不为2万一平的房子辛苦奋斗。我们大 ...

创业投资好项目有很多,说到冷门暴利行业,不禁让人想到低成本高回报,坐拥爆发式机会,有大把大把的银子赚……那 ...

每个年轻人的心中,几乎都有一个事业梦,即便是混迹职场多年的上班族,也会因为工作和生活上的种种压力,到了一定的 ...

互联网中赚钱其实并不难,很多人赚不到钱其实是没有找到正确的方法,但赚钱的本质都是相同的,男人好色,女人爱美,老 ...

有很多的同学是非常的想知道,未来最有前景的十大行业是什么,什么行业赚钱呢,小编整理了相关信息,希望会对大家有所 ...

年轻人创业经验大都不足,面对项目的选择更是一头雾水。不过“男怕入错行”,现在创业,无论男女入错行都是大忌。推荐 ...

最近和人讨论关于有钱人是否真的比其他人聪明,几乎所有人都认为有钱人肯定是比一般人聪明。 对于否定自己智商的事情 ...

[海峡网] 《创业时代》正在热播中,剧中郭鑫年,罗维,金城,三个人是彼此之间的对手。郭鑫年研发的魔晶,罗维研发的 ...

往往赚很多大钱的项目 投资也是非常高的!而身边这些不起眼的投资小的生意.你不起眼他,反而挣得却很多 眼镜店: ...

年轻人是创业群体中的一员。那么,有哪些低成本项目比较适合年轻人来创业呢?下面给大家介绍几个低成本创业项目,希 ...

创业可能是缺钱,也有可能是不满足于现状,不过对于大多数人来说,创业确实是一个摆脱贫穷的方法。当然对于资金不多的 ...

每个地方的街头都有当地人喜欢吃的一些小吃,近些年,越来越多的人成了吃货界的一员,而许多街头卖小吃的商家们,也不 ...

对于很多创业者来说,现在是一个很好的时代,大环境稳定、经济飞速发展、又有不少全能型的人才。创业的门槛,成本 ...

近些年随着新时代的发展,农村创业的机会也越来越多,新农村的建设更是让务工者有了致富的希望,一些人也回家做起了 ...
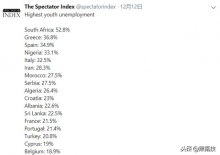
今年不光是中国经济形势不好,全球经济形势也不太好,推特上一个用户公布了全球青年最高失业率的国家:南非: 52.8%; ...

辞职创业是最傻的行为之一,还有借钱创业、无者无畏者创业、不知道干什么创业,想成为大老板的创业,这些思维都是心智 ...

1999年,武昌区中华路街的温冬梅和丈夫都下岗了。温冬梅没有退缩,不久,她和丈夫一起开了间小餐馆卖砂锅煲,并腌制一 ...

现在有很多人整天说找创业机会,其实,创业不用刻意去寻找机会,在生活中、工作中总会遇到有些事情不够完美,那么就 ...

2017年开始了自主创业之路,不到一年生意做得风生水起。“90后” 夫妻创业蒸馒头月入2万多元成名人。 与许多大学生 ...

移动洗车 随着私家车的普及,汽车清洁,美容的需求也不断的扩大。做什么生意投资少?移动洗车项目使用的移动式洗车机 ...

天津政务网今日发布天津市人民政府印发关于做好当前和今后一个时期促进就业工作实施办法的通知。 全文如下—— ...

长相可爱的她喜欢摆弄花草,她靠着糖果花开启了一家店。短短两年时间,她已经挣了将近一百万元。 2003年10月的一天, ...

在杭州,方月中的名字无人不晓。一个骑手单月赚了28000元,并且还在杭州买了房。 说到买房这事,方月中眼角笑出六道 ...

每年加入创业开店大军的都不少,但真正能成功的就屈指可数了,大多数人都死在了开店的路上,那么开店都有哪些死穴?在 ...

2019-04-04 09:59 | 卖家微信公众号 94年出生的王青鹏家里有矿。 王青鹏的父亲是个典型的温州人,走遍国内各个省份 ...

吸收在校生资金,众筹百万开咖啡厅,不到一年未见红利,负责该项目的大学生韩宇也失联。 新京报记者从北京朝阳法院获 ...

用镜头定格精彩瞬间,用心讲述城乡百姓多彩故事,感谢朋友们一直关注我的头条号“定格瞬间美”,每天我会给大家带来 ...

创业是一个系统的工作: 从创业准备、明确市场、成立企业、组建团队、商业计划,管理公司,企业融资等一系列都需 ...
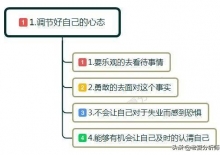
人生的每一步,都不是偶然的,都是你对这个世界的思考和选择 有些事,无能为力,就顺其自然; 有些路,躲避不开,就 ...

原创出品 | 「创业最前线」旗下「科技最前线」 作者 | ? 机场等船 BAT三足鼎立的局面在互联网版图已经持续了十几 ...

我是一个创业失败者,目前是新媒体"16人团队"的一员。 我2015年彻底破产后,负债160多万,人脉尽损,众叛亲离,妻离 ...
 微信扫一扫
微信扫一扫

 匿名
发表于 2023-4-15 09:52:20
匿名
发表于 2023-4-15 09:52:20



